
Poolqualität in großem Maßstab mit Hilfe künstlicher Intelligenz
Sind künstliche Intelligenz und maschinelles Lernen die große Goldgrube im Zeitalter von Big Data? Was steckt hinter diesen viel diskutierten Themen und wie können sie zur Verbesserung der Dienstleistungen eines Unternehmens genutzt werden? Nun, das hängt davon ab, was Sie zu lösen versuchen und wie gut Ihr Datensatz ist. Mit unserer Vision „eine Welt voller glücklicher Nutzer“ im Einklang, nutzen wir KI um unseren Kunden und Testpersonen tatsächlich weiterzuhelfen.

Inhaltsverzeichnis
1. Erfolgreiche Rekrutierung von Testpersonen
TestingTime unterstützt UX Researcher und Marktforscher von bekannten Unternehmen wie Zalando, Swisscom, Trivago, UBS und AXA schneller und preiswerter an reales und verwertbares Nutzerfeedback zu gelangen. Unsere Testpersonen sind unser Kerngeschäft, und was uns von anderen Akteuren auf dem Markt unterscheidet, ist die hohe Qualität unseres Pools von Testpersonen. Wir sorgen für einen repräsentativen und vielfältigen Pool, so dass Sie die für Ihre Nutzerforschung benötigten Profile erhalten. Mit anderen Worten: Wir stellen Ihnen perfekt passende Studienteilnehmer zur Verfügung. Und, was am wichtigsten ist, wir stellen sicher, dass keine Profitester und Studien-Junkies mit dabei sind.
Außerdem sollten sich Moderatoren und Beobachter eines Tests nicht mit No-Shows, kurzfristigen Absagen und verspäteten Testpersonen befassen. Leider wird es immer Ausnahmen geben, in denen der Teilnehmer nicht an einem Test teilnehmen kann, aber es gibt Möglichkeiten, die Risiken von No-Shows auf ein Minimum zu reduzieren. TestingTime hat einige Maßnahmen implementiert, um die No-Show Rate unter dem Industriestandard zu halten. Wir senden unseren Testpersonen zum Beispiel eine E-Mail- und SMS-Bestätigung ihrer Teilnahme sowie eine Erinnerung am Vortag. In diesem Artikel erfahrt ihr, was wir in der Vergangenheit sonst noch gemacht haben und aktuell noch tun, um die Qualität unseres Services sicherzustellen.
2. Experimente mit manuellen Qualitätsprüfungen
In der Vergangenheit haben wir viele Experimente mit manuellen Qualitäts-Kontrollprüfungen durchgeführt, um nicht passende Teilnehmer und potentielle No-Shows zu reduzieren. Zum Beispiel hat unser Customer Success Team jede neue Testperson, die einem Kundenauftrag zugewiesen wurde, angerufen, um die Person zu briefen und den Ablauf des Tests zu erklären. Dies war sehr zeitaufwendig und hatte letztlich keinen Einfluss auf die Qualität der Testperson. In einem anderen Experiment haben wir die Testpersonen gebeten, vor dem Test ein Video von sich selbst aufzunehmen. In diesem Video mussten sie erklären, wer sie sind und was ihre Motivation zur Teilnahme ist. Leider hatte dieses Experiment sogar einen negativen Einfluss auf das Verhalten der Testpersonen. Nach dieser Erfahrung wollten einige Personen so sehr einen guten Eindruck bei den Moderatoren des Tests hinterlassen, dass sie ihnen einfach nur noch gesagt haben, wie gut das Produkt war, anstatt es kritisch zu hinterfragen.
2.1 Umgang mit den Einschränkungen manueller Checks
Bei einem Pool von mehr als einer halben Million Menschen ist es nicht mehr möglich, alle Testpersonen manuell zu überprüfen. Wenn Kunden Testpersonen bei uns bestellen, wollen sie so schnell wie möglich mit ihnen sprechen. Für uns bedeutet das, dass wir so schnell wie möglich herausfinden müssen, welche unserer Testpersonen für den Test geeignet sind. Um Schnelligkeit und Qualität bei zunehmender Panelgröße zu gewährleisten, sind automatisierte Prozesse die einzige Lösung. Die Skalierbarkeit und der Zugriff auf Tausende von Datensätzen haben uns aus diesem Grund dazu veranlasst, 2019 in die Datenwissenschaft zu investieren. Nachdem wir erfolgreiche Ergebnisse bei der Inferenzanalyse gesehen hatten, beschlossen wir, den Sprung zu wagen und 2020 stark in die künstliche Intelligenz zu investieren.
2.2 Gewährleistung von mehr Effizienz und Effektivität dank künstlicher Intelligenz
Um herauszufinden, welche unserer Testpersonen für einen Test geeignet und verfügbar sind, müssen wir unseren Testpersonen Fragen stellen. Dieser Prozess wird als Screening bezeichnet und besteht aus einer Sammlung von Fragen mit eingebauter Logik zum Ein- und Aussortieren der Kandidaten. Jede Rekrutierung von Testpersonen ist mit einem Screening verbunden, bei dem wir prüfen, ob eine Testperson dem Anforderungsprofil eines Kunden entspricht oder nicht. Unsere größte Herausforderung besteht darin, nicht alle 500’000 Testpersonen mit diesen Screeningfragen zu spammen. Aus diesem Grund setzen wir künstliche Intelligenz ein, um unseren Service als Rekrutierer von Testpersonen zu verbessern und die Erfahrung unserer Testpersonen mit uns zu erhöhen. Wir setzen insbesondere zwei Mechanismen der künstlichen Intelligenz ein. Der eine ist für die Profilvorhersage (SmartInvite) und der andere für die Qualitätsvorhersage (Honeybadger).
3. Reduzierung von Mismatching dank SmartInvite
Mismatching ist ein Moment der Frustration für Testpersonen. Vor allem, weil sie sich die Zeit dafür nehmen, die Screener-Fragen zu beantworten und natürlich auf eine Gegenleistung hoffen. Wir tun alles, was wir können, um die Anzahl dieser enttäuschenden Momente zu verringern. An dieser Stelle kommt unser KI “SmartInvite” ins Spiel. Mit Hilfe von SmartInvite können wir zum Beispiel vorhersagen, ob die fiktive Testperson John Meyers tatsächlich einen Tesla besitzt oder nicht. Diese Frage muss John Meyers nicht mal beantworten. Sie fragen sich jetzt wahrscheinlich, wie das funktioniert.
Wir stützen die Profilvorhersage “SmartInvite” auf alle Daten, die wir über den Nutzer und andere Nutzer in unserem System haben. Zum heutigen Tag haben wir über 500’000 Testpersonen und ungefähr 200 Antworten pro Testperson. Unsere Lösung ist eine „Matrix-Faktorisierung“, um jede mögliche Antwort vorherzusagen, wie z.B. “besitzt einen Tesla” und “besitzt einen Mercedes”, aber “besitzt keinen Ferrari”. Basierend auf einem großen Datensatz von über 500’000 Personen mit 200 Antworten pro Person, was zu Millionen von möglichen Antworten (Features) führt, die vorhergesagt werden müssen.
Diese folgende Matrix-Multiplikation zeigt, wie es funktioniert. Die grauen Zahlen zeigen Merkmale (Features), die wir nicht zu 100% wissen, die wir aber mit unserem Vorhersage-Algorithmus berechnen können.
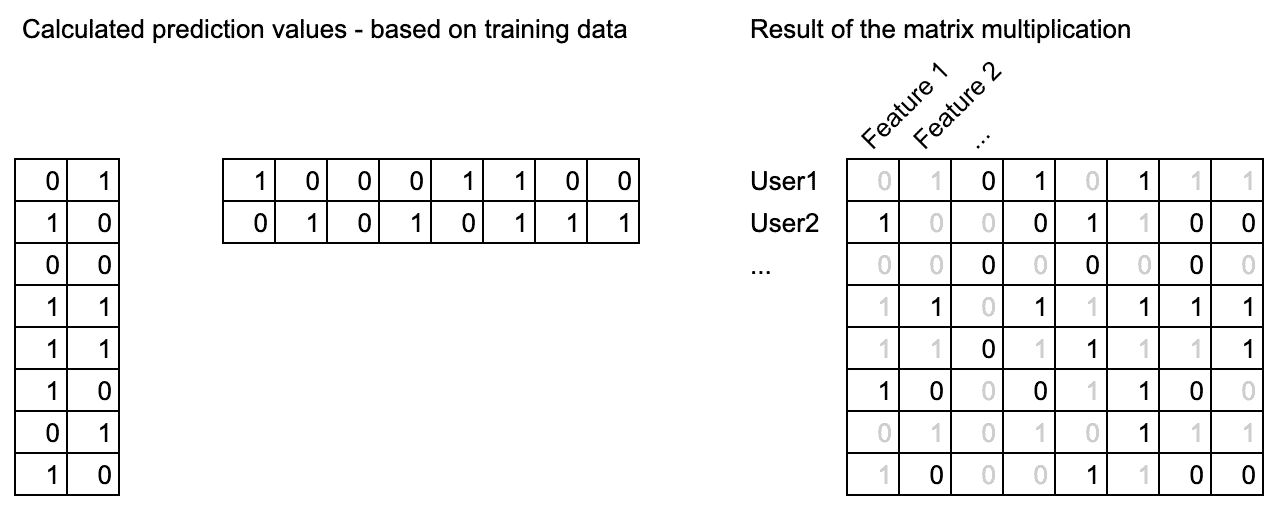
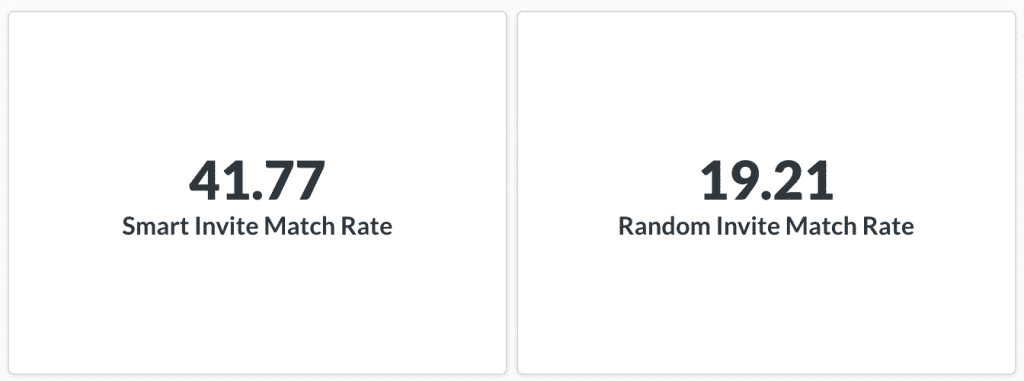
Dank dieses Algorithmus stieg die Wahrscheinlichkeit, dass eine Testperson einem Profil entspricht, von 20% auf 40%.
4. Vorhersage der Zuverlässigkeit dank Honeybadger
Die Benutzerforschung kann für die Organisatoren sehr frustrierend werden, wenn eines dieser beiden Dinge eintritt:
- No-Shows: Testperson taucht nicht auf (oder zu spät, hat den Termin vergessen, der Termin ist ihm egal, Unfall auf dem Weg etc.).
- Misfit: Testperson passt nicht zum gewünschten Profil (Missverständnis in der Kommunikation, Testperson hat beim Screening gelogen etc.).
Der Kern unserer Dienstleistung sind unsere Testpersonen mit höchster Qualität. Für uns und unsere Kunden bedeutet dies, zuverlässige und passende Testpersonen zu liefern. Wir bekämpfen die oben genannten Fälle mit vielen Präventionsmechanismen. Einer von ihnen wird auch durch künstliche Intelligenz angetrieben – wir nennen ihn Honeybadger.
4.1 Clustering von Daten zur Qualitätsvorhersage
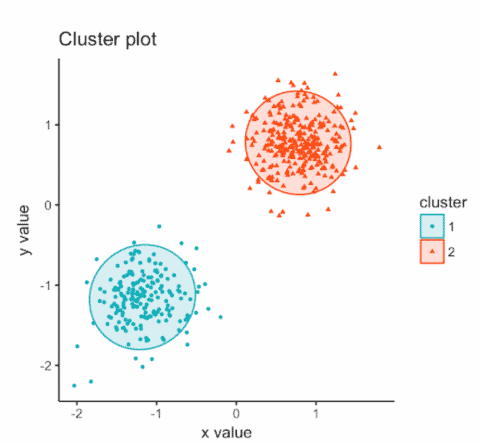
Um herauszufinden, wer für den Test qualifiziert ist, nehmen wir alle Daten, die wir über unsere Testpersonen haben, und klassifizieren sie in zwei Gruppen: die für diesen Test zuverlässige/geeignete Gruppe und die für diesen Test unzuverlässige/ungeeignete Gruppe. Und wir laden nur Testpersonen aus dem geeigneten Cluster ein. Nur um es klarzustellen: Je nach Studienzeit, Sprache, Ort kann es variieren, ob eine Testperson der geeigneten oder der ungeeigneten Gruppe zugeteilt wird. Die nachfolgende visuelle Darstellung zeigt die zwei Dimensionen auf.
4.2 Identifizierung der Faktoren, die die Qualität der Testpersonen beeinflussen
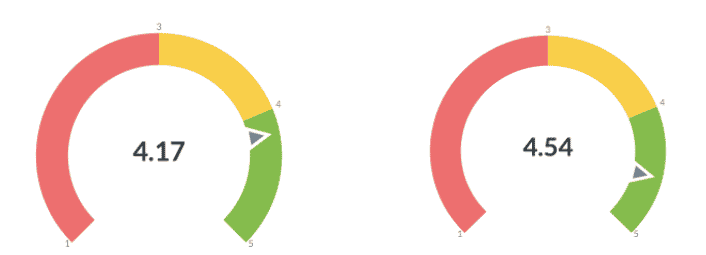
Wir haben mit Hunderten von Einflussfaktoren auf die Qualität experimentiert, wie z.B. „Entfernung zum nächsten Bahnhof“, Wetter (gehen junge Leute lieber am Mittwochnachmittag an den See, wenn es sonnig ist?) etc. Nach einer Weile haben wir sieben gefunden, die wirklich gute Rückschlüsse zulassen. Es bleibt unser Geheimnis, welches diese sieben Faktoren sind. Testpersonen, die von Honeybadger als empfohlen angegeben wurden, erhalten eine Durchschnittsbewertung von 4.54 von 5, während die nicht empfohlenen Personen lediglich eine Durchschnittsbewertung von 4.17 erhalten.
Nur fürs Protokoll: Künstliche Intelligenz ist weit davon entfernt, immer perfekt zu sein. Sie gibt nur Hinweise, und so haben wir unser System aufgebaut. Wir verlassen uns nicht auf den Status Quo, und wir füttern unser System ständig mit neuen Erkenntnissen.
5. Künstliche Intelligenz auf die nächste Stufe bringen
Wie in diesem Artikel erwähnt, verbessern wir kontinuierlich die Qualität unserer Testpersonen-Pools und unseren Service als Rekrutierer von Testpersonen. Die folgenden Schritte zeigen auf, wie wir dies sicherstellen.
5.1 Kontinuierliches Lernen mit neuen Daten
Wir trainieren unseren Prognose-Algorithmus jede Nacht mit all den zusätzlichen Daten, die wir tagsüber gelernt haben. Je länger wir also unseren Algorithmus trainieren und je mehr wir über unsere Testpersonen erfahren, desto mehr profitiert jede Testperson und jeder Kunde von präziseren Vorhersagen. Auf diese Weise belästigen wir unsere Testpersonen nicht mit unnötigen Screener-Einladungen, es sei denn, wir benötigen neue Informationen von ihnen.
5.2 Identifizierung von weiterem Potenzial für künstliche Intelligenz
Eine Sache ist es, die richtigen Testpersonen zu finden, die andere, herauszufinden, wann sie verfügbar sind. Die Vorhersage zur Verfügbarkeit einer Testperson könnte mit Hilfe der künstlichen Intelligenz verbessert werden – wie die Vorhersage der Übereinstimmung einer Testperson. Mit diesem Service könnten wir den Kunden helfen, die Zeitfenster für die Durchführung ihrer Benutzertests zu finden, wenn ihre Zielgruppe hauptsächlich verfügbar ist (z.B. Fabrikmitarbeitende haben normalerweise strenge Zeitpläne). Ein weiterer potenzieller, durch künstliche Intelligenz unterstützter Dienst wäre die Vorhersage der Motivation und der Fähigkeit von Testpersonen, laut zu denken. Zudem könnten Incentive-Vorschläge für die Rekrutierung gewünschter Profile einen relevanten Einfluss auf den ganzen Prozess haben. Die Vorhersage, wie viel Sie Ihrer spezifischen Zielgruppe zahlen sollten, um die richtigen Testpersonen zu gewinnen, könnte die Bereitschaft zur Teilnahme verändern (z.B. haben Studenten und Chirurgen nicht denselben Stundensatz).
6. Das richtige Gleichgewicht zwischen Mensch und Maschine
Die Automatisierung und Digitalisierung des Kundensupports ist ebenfalls ein großartiger Ansatz, um die Effizienz und Schnelligkeit zu verbessern. Wir sind jedoch davon überzeugt, dass es viele Situationen gibt, in denen die Kunden lieber mit einem Menschen sprechen wollen, wenn ihre Fragen nicht vollständig online beantwortet werden können. Deshalb haben wir ein großartiges Team im Einsatz, das sich ausschließlich dem Erfolg unserer Kunden widmet. Auch wenn unsere Prozesse hochgradig digitalisiert und automatisiert sind, um die Qualität unseres Prozesses sicherzustellen, kann der Umgang mit so vielen unterschiedlichen Menschen viele Herausforderungen mit sich bringen. Unser Customer Success-Team kümmert sich um diese Herausforderungen, welche nicht maschinell gelöst werden können. Wir investieren nebst in die künstliche Intelligenz auch in unser Team, um unseren Kunden die bestmögliche Experience zu bieten. Unser Team kann Ihnen mit dem besten Profil-Mix, perfekten Screener-Fragen, der besten Studienmethodik, dem Aufbau Ihres eigenen Pools von Testpersonen (Private Pool) und vielen weiteren Themen helfen.
Head of Product bei TestingTime – Cosima Lefranc ist Head of Product bei TestingTime. Ihre Aufgabe ist es ein rundum großartiges technologisches Produkt zu schaffen. Mit ihrer dualen Qualifikation im Bereich Business Intelligence und Quantitative Finance ist Cosima immer auf der Suche nach neuen datenbasierten Erkenntnissen aus unserer Produktnutzung. Sie liebt es, im direkten Kontakt mit unseren Nutzern zu stehen und neue Wege zu finden, um deren Erfolg weiter zu steigern.

